Classification Tutorial#
This tutorial covers some general concepts in classification and highlights useful functionality in the sklearn package for performing classification.
Classification is closely related to regression. In the case of regression, we're trying to discover a mapping from independent continuous variables onto dependent continuous variables. In the case of classification, we're trying to discover a mapping from independent continuous variables onto dependent categorical (i.e. discrete) variables.
Whereas regression attempts to find the best fit to the data, classification emphasizes finding the best boundaries to separate classes.
One prominent use case in systems neuroscience is that decoding is typically framed as a classification problem. For example, mapping an activity vector (cell activity \(\times\) number of neurons) onto some categorical feature that we believe is represented in that population activity. The category could be which stimulus out of a set of stimuli was presented on that trial, or the behavioral state of the animal (e.g. asleep versus awake, running versus stationary, engaged versus disengaged).
In this tutorial you will learn:
How to use sklearn for linear classification
How to cross-validate your classifier
How to use non-linear classifiers, in this case K nearest neighbors
How to use these classifiers to decode stimulus identify in visual cortex.
import matplotlib.pyplot as plt
import numpy as np
%matplotlib inline
sklearn.datasets provides the ability to generate synthetic data that have specific kinds of structure that are useful for understanding and validating the performance of various classification algorithms.
Here, we’ll generate a 2D dataset with partial overlap.
from sklearn import datasets
X, y = datasets.make_classification(n_features=2,n_redundant=0,random_state=1,n_samples=1000)
print(np.shape(X))
print(np.shape(y))
(1000, 2)
(1000,)
Note that the shape of the independent set \(X\) is (num_samples, num_dimensions) and the dependent set \(y\) is (num_samples).
The following function can visualize the datasets we’ll generate in this tutorial.
def plot_classes(X, y, xlabel=None, ylabel=None, names=None, ax=None):
classes = np.unique(y)
# This code grabs the default color sequence, so that our
# colors will match other plots
prop_cycle = plt.rcParams['axes.prop_cycle']
color = prop_cycle.by_key()['color']
if ax is None:
ax = plt.figure(figsize=(8, 8)).gca()
# Loop through classes
for ii,cl in enumerate(classes):
if names is not None: # If 'names' was passed, use this for label
this_label = names[ii]
else:
this_label = f'Class {cl}' # If 'names' was passed, otherwise use class number
ax.scatter(X[y==ii,0], X[y==ii,1], c=color[ii], edgecolor='none', label=this_label)
ax.set_xlim(X[:,0].min(), X[:,0].max())
ax.set_ylim(X[:,1].min(), X[:,1].max())
ax.set_xlabel(xlabel) # Optionally label axes
ax.set_ylabel(ylabel) # Optionally label axes
ax.legend()
plt.show()
return ax # Return the axis handle, in case we want to do more with it
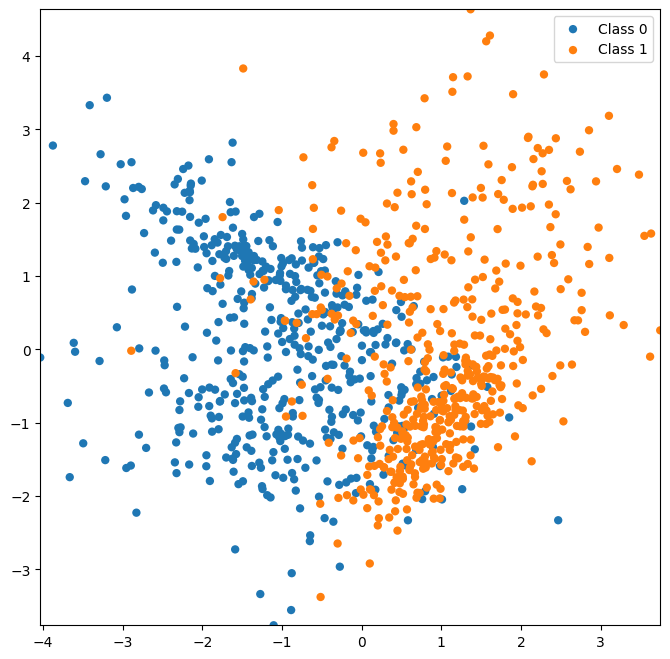
Let’s plot our data to get an idea of what it looks like.
ax = plot_classes(X, y);
Now let’s train a classifier to predict the class of a given point.
It’s important to split our data into a train and test set to ensure that our classifier can generalize to data that it hasn’t yet seen. Again sklearn provides a straightforward function to make this split. Here, by specifying test_size=0.2, We’re telling the function that we want 20% of the data held-out for testing.
from sklearn import model_selection
X_train, X_test, y_train, y_test = model_selection.train_test_split(X, y, test_size=0.2)
print(np.shape(X_train))
print(np.shape(y_train))
(800, 2)
(800,)
Linear Discriminant Analysis#
The first classification algorithm we’ll try, and one typically worth trying first, is linear discriminant analysis. LDA will attempt to find a linear boundary between our classes.
Here’s more information on Linear Discriminant Analysis if you want to learn more.
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis as LDA
classifier = LDA()
classifier.fit(X_train, y_train)
y_hat = classifier.predict(X_test)
The fit method trains the classifier to learn the categories from the training data X_train and y_train, then the predict method predicts the label of each point in our test set X_test.
This next function can visualize the test data that are correctly versus incorrectly classified. Correctly classified data are displayed as filled circles, whereas incorrectly classified data are displayed as open circles.
def plot_test_performance(X, y, y_hat, xlabel=None, ylabel = None, names = None, ax = None):
classes = np.unique(y_test)
num_classes = len(classes)
prop_cycle = plt.rcParams['axes.prop_cycle']
color = prop_cycle.by_key()['color']
if ax is None:
ax = plt.figure(figsize=(8,8)).gca()
for ii,cl in enumerate(classes):
if names is not None: # If 'names' was passed, use this for label
this_label = names[ii]
else:
this_label = f'Class {cl}' # If 'names' was passed, otherwise use class number
# Determine which points were correct (or not)
is_class = y == cl
is_correct = y == y_hat
# Plot correctness with labels
ax.scatter(X[is_class & is_correct,0],X[is_class & is_correct,1],c=color[cl],edgecolor='none',label = this_label + ' correct')
ax.scatter(X[is_class & ~is_correct,0],X[is_class & ~is_correct,1],c='none',edgecolor=color[cl],label =this_label + ' incorrect')
ax.set_xlim(X[:,0].min(),X[:,0].max())
ax.set_ylim(X[:,1].min(),X[:,1].max())
ax.set_xlabel(xlabel)# Optionally label axes
ax.set_ylabel(ylabel)# Optionally label axes
ax.legend()
plt.show()
return ax
Let’s look at which points were correctly classified in our test data.
plot_test_performance(X_test,y_test,y_hat);
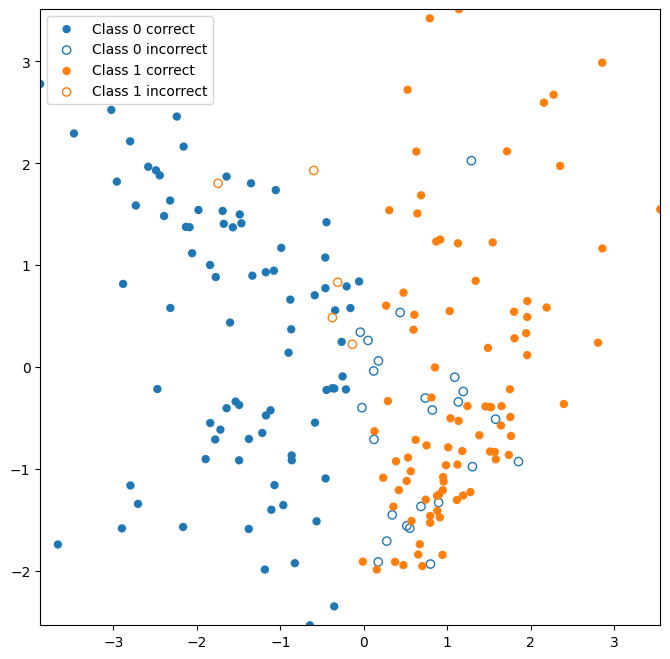
Note that an open circle indicates that the data point should belong to the given class, but was incorrectly classified as another class (e.g. A “Class 1 incorrect” point should belong to Class 1, but was predicted to belong to Class 0).
Classifiers create a decision boundary between regions that will be classified differently. Visualizing the decision boundary can be useful to understand what the model believes about the classes. sklearn provides a handy class called DecisionBoundaryDisplay to aid in this. We’ll create a simple wrapper function to create some useful defaults:
from sklearn.inspection import DecisionBoundaryDisplay
from matplotlib.colors import LinearSegmentedColormap
def plot_classifier_boundary(classifier, X, num_classes=2, ax = None):
if ax is None:
ax = plt.figure(figsize=(8,8)).gca()
prop_cycle = plt.rcParams['axes.prop_cycle']
color = prop_cycle.by_key()['color']
cmap = LinearSegmentedColormap.from_list('blue-orange', color[:num_classes], N=num_classes)
DecisionBoundaryDisplay.from_estimator(classifier,X, plot_method='contourf', response_method='predict', cmap=cmap, ax=ax, alpha=0.5)
return ax
Now let’s take a look at the decision boundary for our classifier.
ax = plot_classifier_boundary(classifier,X)
ax = plot_test_performance(X_test,y_test,y_hat, ax=ax);
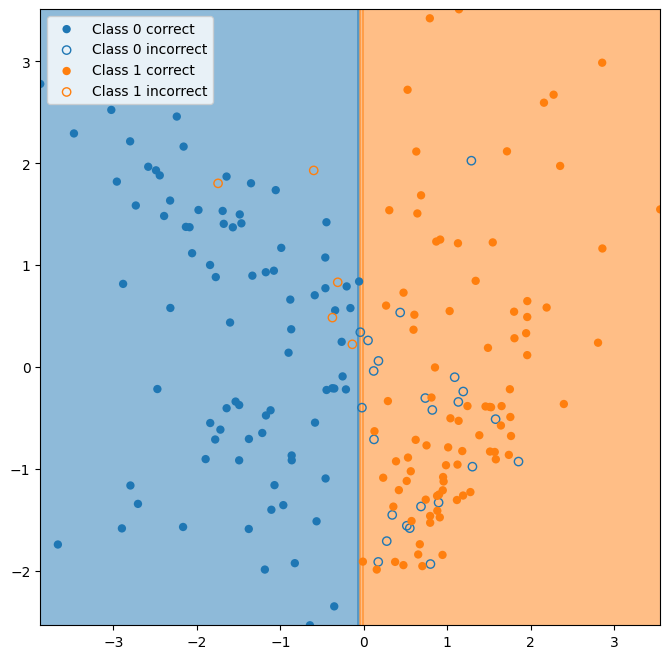
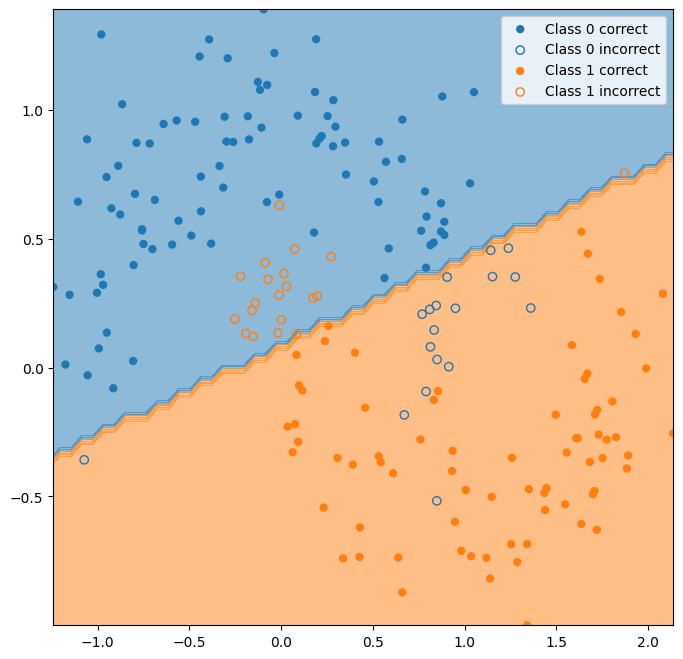
The classifier essentially learns to classify the data based on whether the first dimension is greater than or less than zero.
The next exercise illustrates an important aspect of training classifiers: since the classifier learns both the generalizable structure of the data that we’re trying to capture as well as the specific variation (noise) in the training data, the performance of a classifier can be no better on the test data than on the training data. Typically, it’s worse. This phenomenon is called overfitting. Overfitting is characterized by poor accuracy on the test dataset, while accuracy in training remains high. Overfitting indicates that the classifier has learned too much of the noise present in the training data.
train_accuracy = []
test_accuracy = []
num_folds = 5
X, y = datasets.make_classification(n_features=2,n_redundant=0,random_state=0,n_samples=20)
scores = model_selection.cross_validate(classifier,X,y, cv=5, return_train_score=True)
plt.figure(figsize=(8,8))
ax = plt.subplot(111)
ax.bar([0,1],[np.mean(scores['train_score']),np.mean(scores['test_score'])],color='c')
ax.set_xticks([0,1])
ax.set_xticklabels(['Train','Test'],fontsize=16)
ax.set_ylabel('Fraction Correct',fontsize=16)
plt.show()
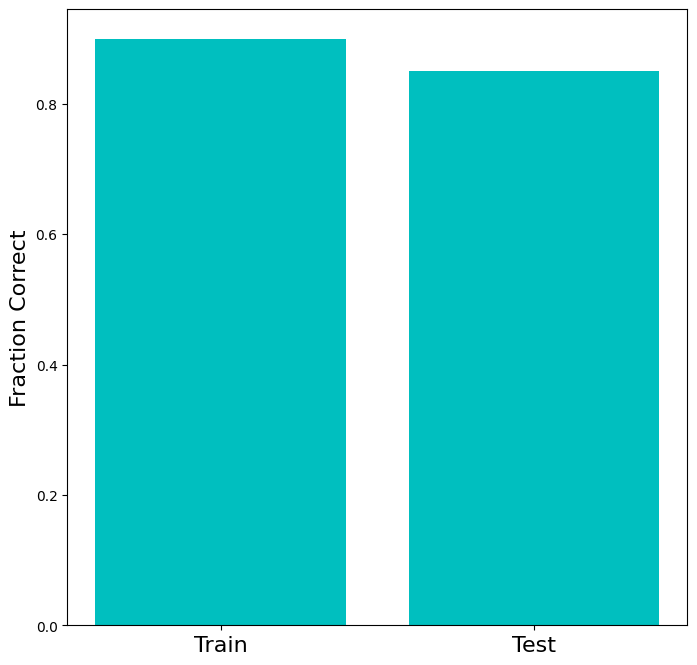
Try playing with the number of samples in the dataset above. You’ll notice that the gap between the performance on train and test sets gets smaller as the dataset gets larger. That happens because the sample dataset begins to look more like the full population, so large train and test set should have very similar distributions. In other words, as the training set becomes infinitely large, it becomes impossible that the test set encounters a part of the distribution that is not represented in the train set.
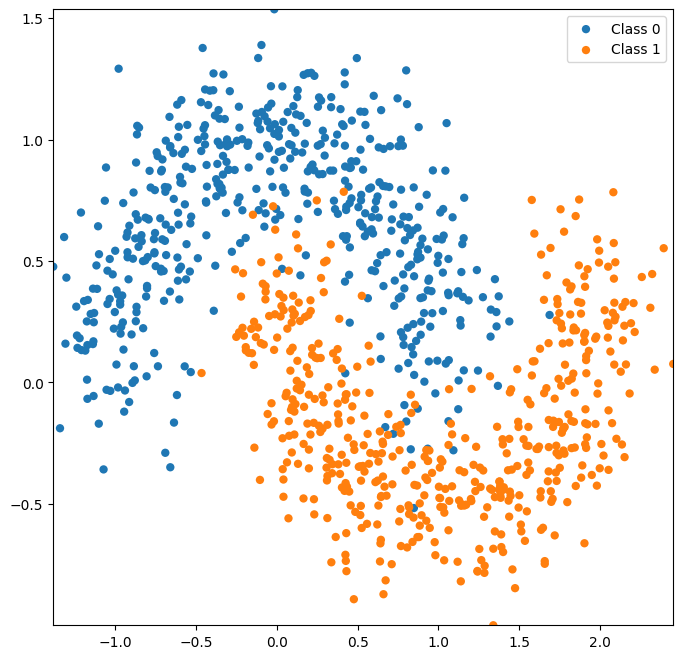
Next, let’s try a dataset that isn’t so easily separated by a linear classifier.
X, y = datasets.make_moons(noise=0.2,random_state=0,n_samples=1000)
plot_classes(X,y);
X_train, X_test, y_train, y_test = model_selection.train_test_split(X,y,test_size=0.2)
classifier = LDA()
classifier.fit(X_train,y_train)
y_hat_lda = classifier.predict(X_test)
ax = plot_classifier_boundary(classifier,X)
plot_test_performance(X_test,y_test,y_hat_lda, ax=ax);
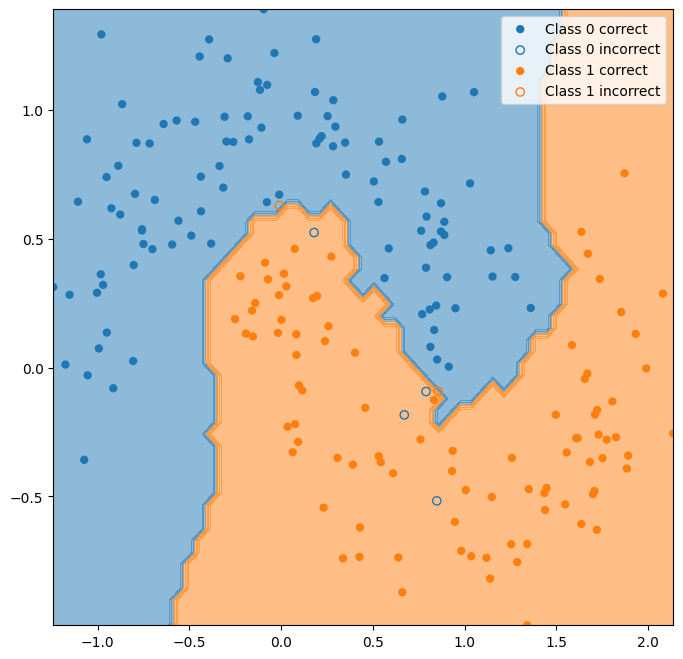
K-nearest neighbors#
Let’s try a non-linear classifier. K-nearest neighbors is a very straightforward non-linear classifier that just uses the class mode of the closest data points in the training set.
Here’s more on K-nearest neighbors if you want to learn more.
from sklearn import neighbors
classifier = neighbors.KNeighborsClassifier()
classifier.fit(X_train, y_train)
y_hat_knn = classifier.predict(X_test)
ax = plot_classifier_boundary(classifier, X)
plot_test_performance(X_test, y_test, y_hat_knn, ax=ax);
The performance of the KNN classifier depends on the number of neighbors that are considered for deciding class membership. We can determine the best value of K through validation.
from sklearn import neighbors
k_to_try = np.arange(2, 250, 1)
val_performance = np.zeros(np.shape(k_to_try))
for ki, k in enumerate(k_to_try):
classifier = neighbors.KNeighborsClassifier(n_neighbors=k)
scores = model_selection.cross_validate(classifier, X_train, y_train, cv=3)
val_performance[ki] = np.mean(scores['test_score'])
plt.figure(figsize=(8, 8))
plt.plot(k_to_try, val_performance, 'ro')
plt.xlabel('K', fontsize=16)
plt.ylabel('Validation Performance', fontsize=16)
plt.show()
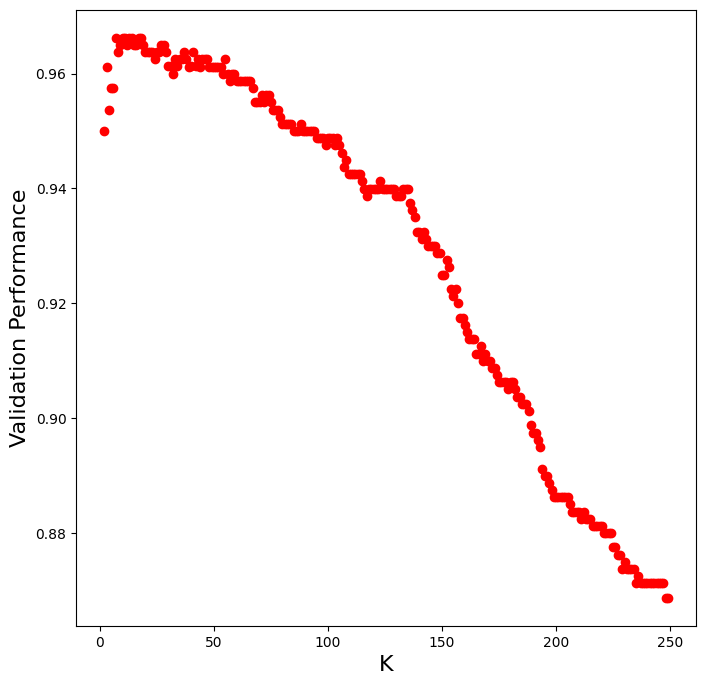
Now let’s use the best value of K from validation to see how well it generalizes to the hold-out test set.
best_K = k_to_try[np.argmax(val_performance)]
classifier = neighbors.KNeighborsClassifier(n_neighbors=best_K)
classifier.fit(X_train,y_train)
y_hat = classifier.predict(X_test)
print("Best K: " + str(best_K))
print("Validation Performance: " + str(val_performance.max()))
print("Test Performance: " + str(np.mean(y_test == y_hat)))
Best K: 7
Validation Performance: 0.9662545877803123
Test Performance: 0.975
Let’s quantitatively compare the performance of LDA and KNN.
test_accuracy = np.array([
(y_test==y_hat_lda).mean(),
(y_test==y_hat_knn).mean()
])
plt.figure(figsize=(8,8))
ax = plt.subplot(111)
ax.bar([0,1],test_accuracy,color='c')
# ax.set_xticks([0.25,1.25])
ax.set_xticks([0,1])
ax.set_xticklabels(['LDA','KNN'],fontsize=16)
ax.set_ylabel('Fraction Correct',fontsize=16)
plt.show()
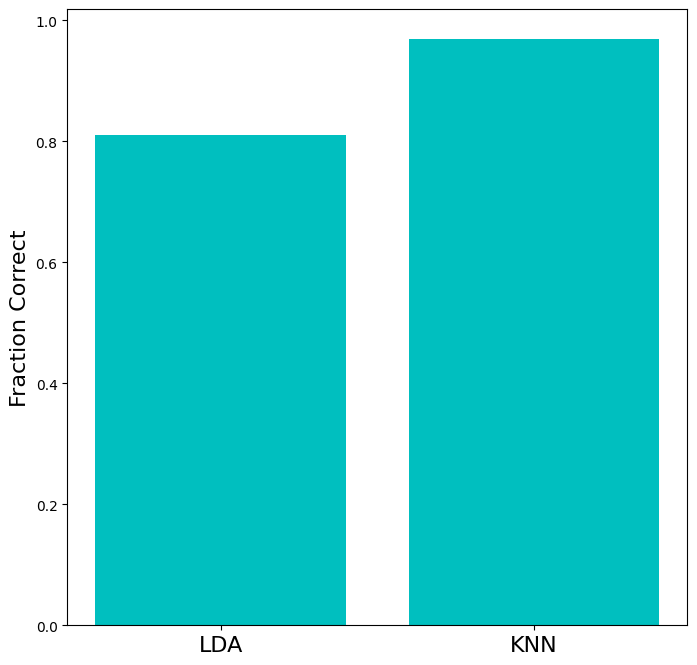
There are many more types of datasets you can make with scikit-learn, many of which are not linearly classifiable. See the sklearn-documentation on generated datasets for more datasets and information.
X, y = datasets.make_circles(noise=0.1, factor=0.5, random_state=1,n_samples=1000)
plot_classes(X,y);
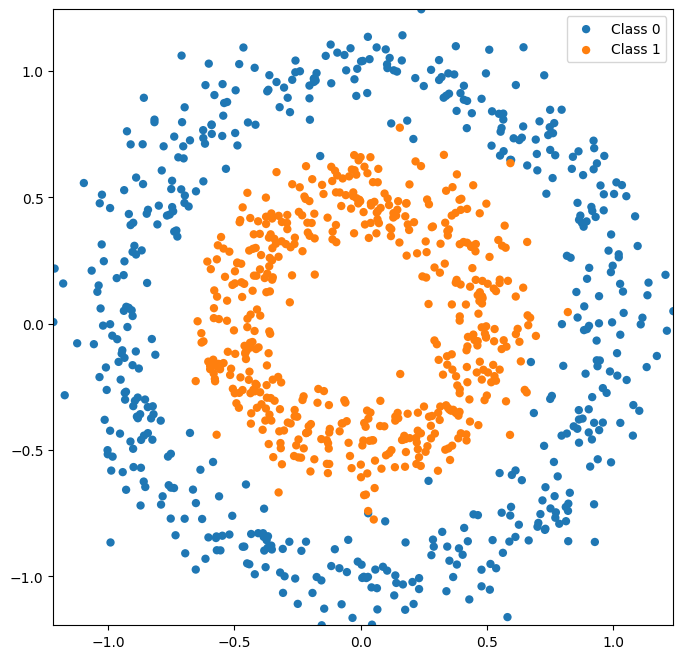
Now let’s look at a dataset with more than two classes.
X, y = datasets.make_blobs(n_features=2, centers=3, random_state=4, n_samples=1000)
plot_classes(X,y);
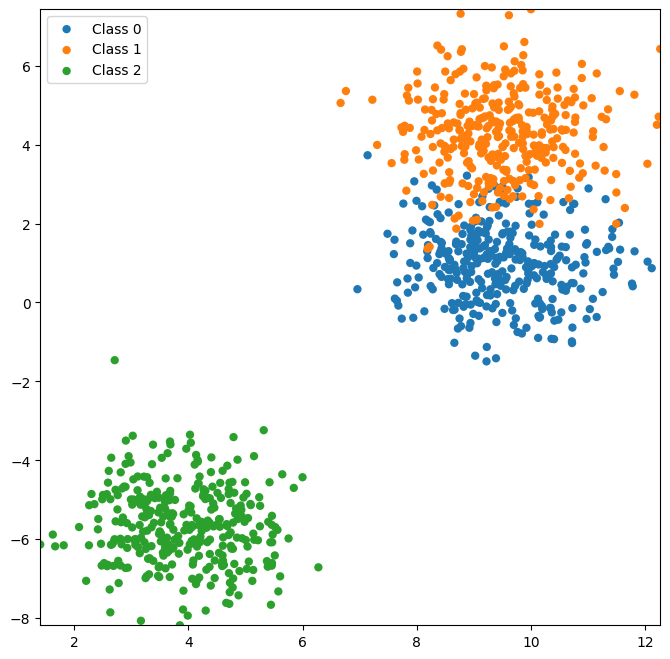
X_train, X_test, y_train, y_test = model_selection.train_test_split(X, y, test_size=0.2)
classifier = neighbors.KNeighborsClassifier()
classifier.fit(X_train, y_train)
y_hat = classifier.predict(X_test)
ax = plot_classifier_boundary(classifier, X, num_classes=3)
plot_test_performance(X_test, y_test, y_hat, ax=ax);
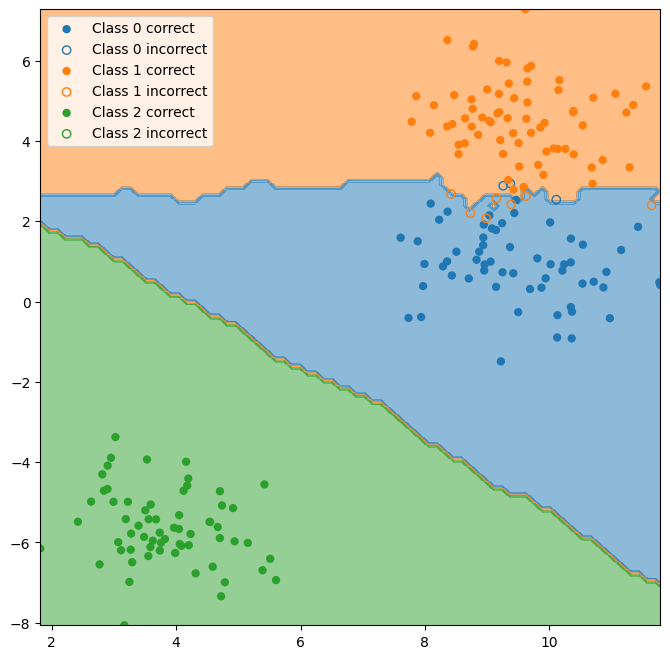
Note that the red and blue classes overlap, but neither overlaps with the green class. One method commonly used to determine which classes are more difficult for a classifier to distinguish is to make a “confusion matrix.” This is simply a matrix comparing the actual class to which a data point belongs with the class that is predicted by the classifier.
Confusion Matrix#
from sklearn.metrics import confusion_matrix
C = confusion_matrix(y_test, y_hat, normalize = 'all')
# Note that normalization is needed when all classes are not of the same size
# The default is to plot based on counts
classes = ['Class 0', 'Class 1', 'Class 2']
plt.figure(figsize=(8, 8))
ax = plt.subplot(111)
cax = ax.imshow(C,interpolation='none', vmin=0, vmax=C.max())
ax.set_xlabel('Predicted Class', fontsize=16)
ax.set_ylabel('Actual Class', fontsize=16)
ax.set_xticks(range(3))
ax.set_xticklabels(classes, fontsize=16)
ax.set_yticks(range(3))
ax.set_yticklabels(classes, fontsize=16)
cbar = plt.colorbar(cax)
cbar.set_label('Performance')
plt.show()
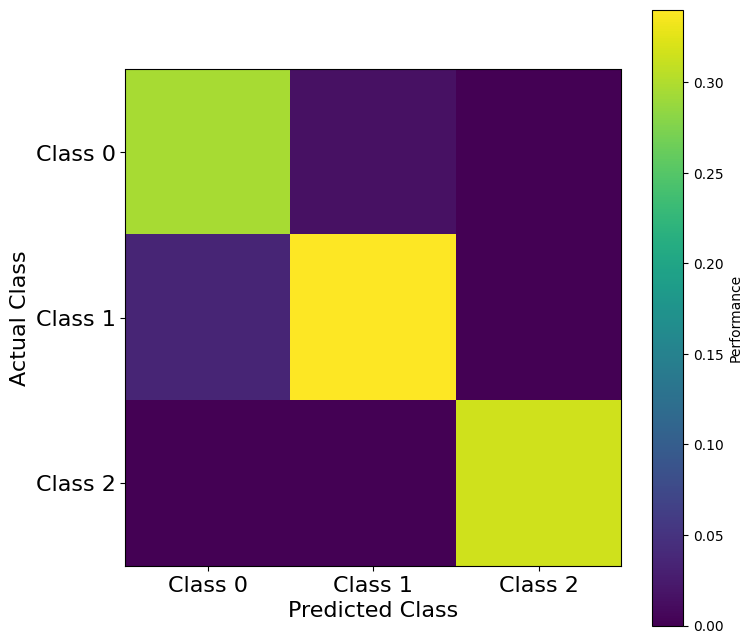
Note that Class 2 is predicted with high accuracy, while Class 0 and Class 1 are predicted with lower accuracy. Especially, Class 1 is sometimes incorrectly predicted as Class 0, and to a lesser extent, Class 0 is sometimes incorrectly predicted as Class 1.
Side note: Classification is related to another technique called clustering. Classification is performed when you have class labels, whereas clustering is performed when predefined labels do not exist for the data. The former is known as supervised learning and the latter is known as unsupervised learning. sklearn, as you might have guess, has a number of built in clustering algorithms. As with classification, different algorithms make different underlying assumptions about the data at hand. You can read about these here.
Once again, let’s try to perform decoding in the Visual Behavior dataset.#
Specifically, we will try and decode which image was presented to a mouse during a string of behavior trials
import allensdk
from allensdk.brain_observatory.\
behavior.behavior_project_cache.\
behavior_neuropixels_project_cache \
import VisualBehaviorNeuropixelsProjectCache
import os
import platform
platstring = platform.platform()
if 'Darwin' in platstring or 'macOS' in platstring:
# macOS
data_root = "/Volumes/Brain2022/"
elif 'Windows' in platstring:
# Windows (replace with the drive letter of USB drive)
data_root = "E:/"
elif ('amzn' in platstring):
# then on AWS
data_root = "/data/"
else:
# then your own linux platform
# EDIT location where you mounted hard drive
data_root = "/media/$USERNAME/Brain2022/"
# cache = VisualBehaviorNeuropixelsProjectCache.from_s3_cache(cache_dir=cache_dir)
cache = VisualBehaviorNeuropixelsProjectCache.from_local_cache(
cache_dir=data_root, use_static_cache=True)
/opt/envs/allensdk/lib/python3.10/site-packages/tqdm/auto.py:21: TqdmWarning: IProgress not found. Please update jupyter and ipywidgets. See https://ipywidgets.readthedocs.io/en/stable/user_install.html
from .autonotebook import tqdm as notebook_tqdm
We are going to examine the session looking at familiar images that contains the most V1 units.
area = 'VISp'
# You have actually seen this code before, so we won't spend time on it...
units_table = cache.get_unit_table()
ecephys_sessions_table = cache.get_ecephys_session_table()
# For now, we are going to grab the one with the most V1 units.
unit_by_session = units_table.join(ecephys_sessions_table,on = 'ecephys_session_id')
unit_in = unit_by_session[(unit_by_session['structure_acronym']==area) &\
(unit_by_session['experience_level']=='Familiar') &\
(unit_by_session['isi_violations']<.5)&\
(unit_by_session['amplitude_cutoff']<0.1)&\
(unit_by_session['presence_ratio']>0.95)]
unit_count = unit_in.groupby(["ecephys_session_id"]).count()
familiar_session_with_most_in_units = unit_count.index[np.argmax(unit_count['ecephys_probe_id'])]
# Actually import the data
session = cache.get_ecephys_session(ecephys_session_id=familiar_session_with_most_in_units)
/opt/envs/allensdk/lib/python3.10/site-packages/hdmf/utils.py:668: UserWarning: Ignoring cached namespace 'core' version 2.6.0-alpha because version 2.7.0 is already loaded.
return func(args[0], **pargs)
Now we will transform the data to be a dictionary of spike times for each unit.
# Get unit information
session_units = session.get_units()
# Channel information
session_channels = session.get_channels()
# And associate each unit with the channel on which it was found with the largest amplitude
units_by_channels= session_units.join(session_channels,on = 'peak_channel_id')
# Filter for units in primary visual cortex
this_units = units_by_channels[(units_by_channels.structure_acronym == area)\
&(units_by_channels['isi_violations']<.5)\
&(units_by_channels['amplitude_cutoff']<0.1)\
&(units_by_channels['presence_ratio']>0.95)]
# Get the spiketimes from these units as a dictionary
this_spiketimes = dict(zip(this_units.index, [session.spike_times[ii] for ii in this_units.index]))
Next, get the stimulus table for the behavior session:
active_stims = session.stimulus_presentations[session.stimulus_presentations.stimulus_block==0 ]
We are going to look at time bins after each stimulus presentation, so we will count the number of spikes 0-50ms after each presentation, 50-100ms after each presentation, etc. This is very similar to constructing a PSTH, but we are going to keep each neurons response on each trial separate so that we can try to decode trial identity. This will give as a matrix Xbins with dimensions (Trials, Neurons, TimeBins).
# Look we want to look at time 750 ms after the start of the trial.
dt = .05 # Time is in seconds
time = np.arange(0,.75+dt,dt)
time
array([0. , 0.05, 0.1 , 0.15, 0.2 , 0.25, 0.3 , 0.35, 0.4 , 0.45, 0.5 ,
0.55, 0.6 , 0.65, 0.7 , 0.75])
# Declare and empty variable X
Xbins = np.zeros((len(active_stims),len(this_spiketimes),len(time)-1))
# This Loop is a little slow...be patient
for jj,key in enumerate(this_spiketimes):
# Loop through the trials
for ii, trial in active_stims.iterrows():
startInd = np.searchsorted(this_spiketimes[key], trial.start_time)
endInd = np.searchsorted(this_spiketimes[key], trial.start_time+.75+dt)
# Count the number of spikes per trial.
Xbins[ii,jj,:] = np.histogram(this_spiketimes[key][startInd:endInd]-trial.start_time,time)[0]
To decode image identity, what we actually need is is (𝑇,𝑛) matrix with row per time sample and one column per neuron/dimension. Why did we just go to the trouble of constructing such a fancy Xbins? The reason is that it gives us the flexibility to look at how well activity can be decoded from different epochs of a given image presentation. Lets start by trying to decode activity between 0 and 250 ms after the start of the trial.
X250 = np.sum(Xbins[:,:,time[:-1]<=.250],axis=2)
X250.shape
(4797, 110)
The np.unique command in NumPy has a handy feature that converts non-numeric catagories to numeric ones.
np.unique returns a list of each unique value in a list. The inverse of the unique function provides the index needed to return that list back to its original state. Conveniently, for a discrete variable, this means that the inverse returned by the unique function provides a integer category marker for non-integer data.
[unq,cat]= np.unique(active_stims.image_name,return_inverse=True)
unq
array(['im005_r', 'im024_r', 'im034_r', 'im083_r', 'im087_r', 'im104_r',
'im111_r', 'im114_r', 'omitted'], dtype=object)
An unsupervised approach#
We should take a moment to note that unsupervised learning and dimensionality reduction techniques, like PCA, are often useful in assessing how successful a decoding algorithm might be. If you can easily visualize stratification in your data, it will likely be easy for a classifier to determine boundaries between groups in your data. Lets take a moment to look at the first two PCs of our response matrix, X. Do you think we are going to have much luck with our classifier?
from sklearn.decomposition import PCA
pca = PCA()
trans = pca.fit_transform(X250)
plot_classes(trans[:,:2],cat,xlabel = 'PC1',ylabel = 'PC2',names = unq);
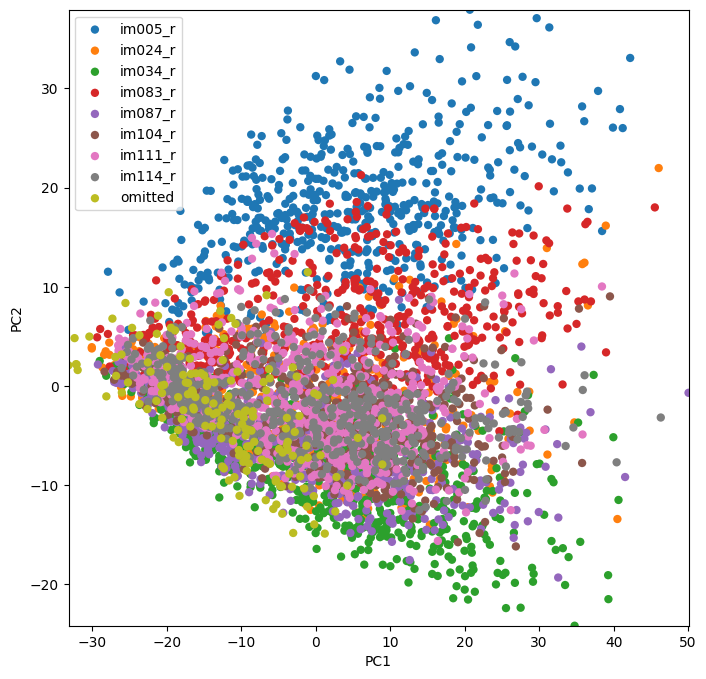
Looks like this is likely going to work!
A Supervised Approach#
We are now ready to try decoding from X250! As before, we start by splitting into training and testing data.
X_train, X_test, cat_train, cat_test = model_selection.train_test_split(
X250, cat,
test_size=0.2,
stratify=cat, # this makes sure that our training and testing sets both have all classes in y
)
# Fit the classifier
classifier250 = LDA()
classifier250.fit(X_train,cat_train)
cat_hat = classifier250.predict(X_test) #NOW you know why this variable was called "cat"
# And Visuallize the confusion matrix
C = confusion_matrix(cat_test,cat_hat,normalize='true')
plt.figure(figsize=(8,8))
ax = plt.subplot(111)
cax = ax.imshow(C,interpolation='none',vmin=0,vmax=C.max())
ax.set_xlabel('Actual Class',fontsize=16)
ax.set_ylabel('Predicted Class',fontsize=16)
ax.set_xticks(np.arange(0,9))
ax.set_xticklabels(unq, rotation = 45)
ax.set_yticks(np.arange(0,9))
ax.set_yticklabels(unq, rotation = 45)
plt.colorbar(cax)
plt.show()
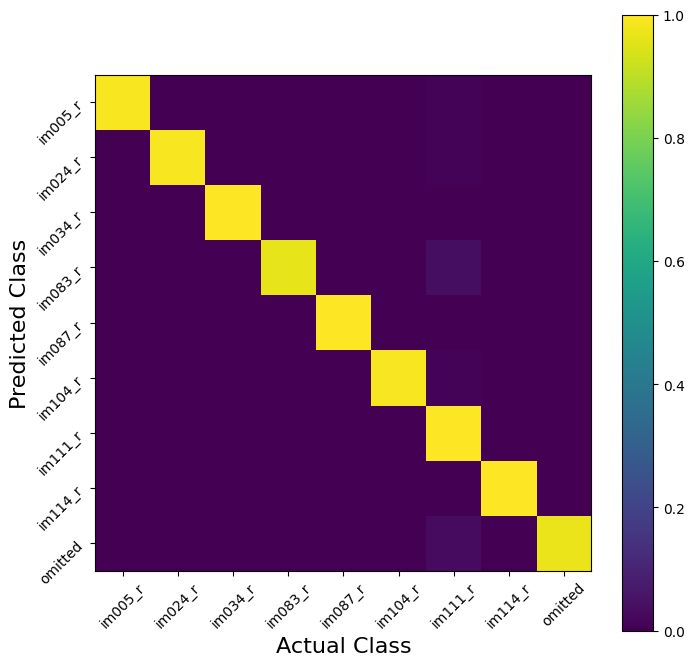
V1 was a (maybe too) easy example for this problem. To see this, we can use cross validation to estimate the performance of our model. Our decoding is very nearly perfect! This is how you know you are seeing a cherry-picked tutorial example…it almost never happens in real life…
scores = model_selection.cross_val_score(classifier250, X250, cat, cv=5)
scores
array([0.98958333, 0.97916667, 0.98331595, 0.9822732 , 0.99270073])
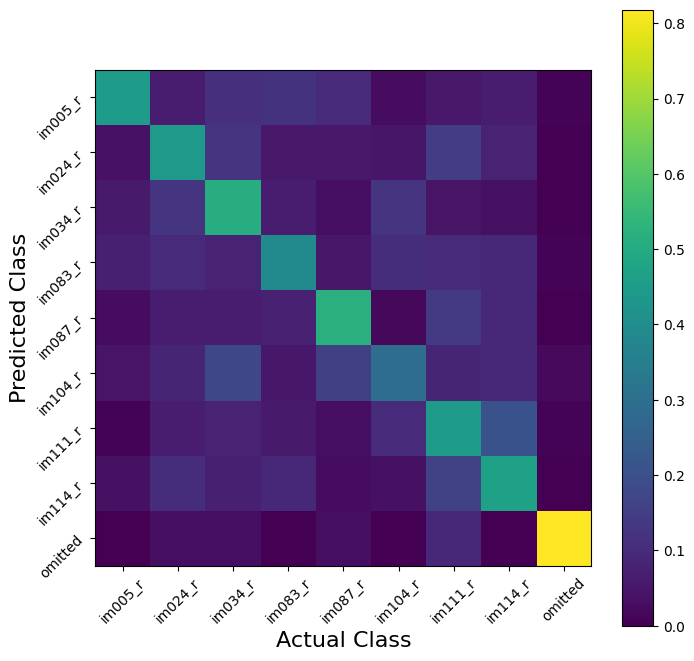
The structure of our Xbins matrix, however, allows us to ask harder questions. Lets say, for example, we want to try to decode image identity in the 250ms AFTER the image presentation:
# Get the prediction matrix for this time epoch
X500 = np.sum(Xbins[:,:,np.bitwise_and(time[:-1]<=.750,time[:-1]>.500)],axis=2)
classifier500 = LDA()
scores = model_selection.cross_val_score(classifier500, X500, cat, cv=5)
scores
array([0.35833333, 0.41458333, 0.43274244, 0.40458811, 0.37643379])
Suddenly, decoding doesn’t seem so easy!
We are still doing ‘OK,’ in that we decode image identity better with accuracy better than guessing, but not as well as before. Now the confusion matrix becomes more useful; we can ask whether decoding errors are the same for all images. Are some stimuli less often confused than others later in the presentation sequence?
X_train_500, X_test_500, cat_train_500, cat_test_500 = model_selection.train_test_split(
X500, cat,
test_size=0.2,
stratify=cat, # this makes sure that our training and testing sets both have all classes in y
)
# Fit the model we delared earlier
classifier500.fit(X_train_500,cat_train_500)
cat_hat_500 = classifier500.predict(X_test_500) #NOW you know why this variable was called "cat"
# And Visuallize the confusion matrix
C = confusion_matrix(cat_test_500,cat_hat_500,normalize='true')
plt.figure(figsize=(8,8))
ax = plt.subplot(111)
cax = ax.imshow(C, interpolation='none', vmin=0, vmax=C.max())
ax.set_xlabel('Actual Class', fontsize=16)
ax.set_ylabel('Predicted Class', fontsize=16)
ax.set_xticks(np.arange(0,9))
ax.set_xticklabels(unq, rotation = 45)
ax.set_yticks(np.arange(0,9))
ax.set_yticklabels(unq, rotation = 45)
plt.colorbar(cax)
plt.show()
It is also worth noting that models fit in one condition can be applied to another. This can be useful it trying comparing population representations between conditions. We might, for example, want to know how well a model fit to the first 250ms of each image presentation (X250) does at predicting the identity during the next 250ms (X500). This will will give us a sense of whether neurons in the population qualitatively change their image preference once the stimulus turns off, or whether there responses are simply less consistent.
score = classifier250.score(X500,cat)
score
0.059203668959766524
This question can be asked in either direction.
score = classifier500.score(X250,cat)
score
0.34542422347300394
Exercise 1: We built the Xbins array to be more fine grained than we have used thus far. Loop through each in this array and cross validate a linear classifier using each time bin. Plot the scores relative to the time from stimulus onset.#
Exercise 2: All of the examples so far have relied on a linear classifier - one of the simplest available classifiers. Once you have your classifier in exercise one working, try using the sklearn interface to sub in a different classification class. Do you do better (or worse) with a different classifier?#
Understanding the model behind different classification methods can help understand why some do better than others. We have already covered some of the classifiers implemented in sklearn, but a complete list is available here: https://scikit-learn.org/stable/supervised_learning.html. Further, there is a Pipeline tutorial (in this folder) that we will not have time to cover this year. If you want some tips on automated methods for model selection, this is a good place to start.
Think for a moment about what the difference in performance between the linear model and your chosen model tells you about either your model or the V1 population.
Getting more from a classifier#
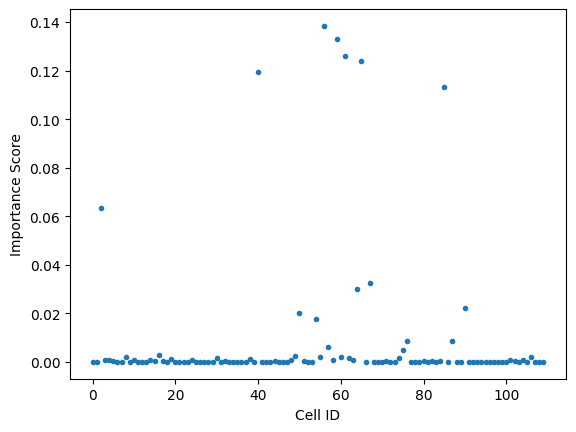
Finally, it’s worth noting that some classifiers can measure how important an particular feature was in making their classification.
One example of this is a decision tree. Decision trees are useful because the results are easily interpretable - in the end, you get a series of choices on the values of individual features that tell you which class to assign any given data point to. They’re called decision trees because you always start at the same point (“the root”) and each consecutive choice leads you down a particular branch, until you arrive at a class assignment (“the leaves”).
A Decision tree object also returns a “feature_importances_” variable. Feature importance (see “Gini Importance”) gives a sense of how heavily each feature is weighted in the decision tree. In this case, It tells us how important each cell is in the classifier’s decision process.
from sklearn.tree import DecisionTreeClassifier
classifier = DecisionTreeClassifier(random_state=0)
classifier = classifier.fit(X_train, cat_train)
plt.plot(classifier.feature_importances_,'.')
plt.xlabel("Cell ID")
plt.ylabel('Importance Score')
plt.show()