Accessing Dynamic Foraging data#
The Dynamic foraging task is being used to study and model decision making, and is being combined with other modalities of physiology data including electrophysiology and fiber photometry to explore how neurons, networks, and neuromodulators are involved in the task.
At this time, we are sharing ~400 sessions of behavior only sessions of the Dynamic Foraging task, including sessions from different stages of training. The mice in these session are likely being trained for different ultimate experiments (e.g. fiber photometry or ephys), and so there is a range of different procedural preparations (e.g. different genotypes and viral injections). But the behavior is all the same task.
Looking at the metadata#
TODO
Loading a session#
These data can be loaded using pynwb
from hdmf_zarr import NWBZarrIO
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
session_path = '/data/behavior_761433_2025-03-27_08-51-54_processed_2025-03-28_05-00-28/nwb/behavior_761433_2025-03-27_08-51-54.nwb'
io = NWBZarrIO(session_path, "r")
nwb = io.read()
Because there is only the behavioral task, these files are smaller and simpler than many of the physiology NWB files.
Trials#
The trials table documents the parameters and behavior of each trial.
trials = nwb.intervals['trials'][:]
trials.head()
| start_time | stop_time | animal_response | rewarded_historyL | rewarded_historyR | delay_start_time | goCue_start_time | reward_outcome_time | side_bias | side_bias_confidence_interval | ... | auto_train_curriculum_version | auto_train_curriculum_schema_version | auto_train_stage | auto_train_stage_overridden | lickspout_position_x | lickspout_position_y1 | lickspout_position_y2 | lickspout_position_z | reward_size_left | reward_size_right | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| id | |||||||||||||||||||||
| 0 | 8.366000e+06 | 8.366007e+06 | 0.0 | False | False | 8.366005e+06 | 8.366006e+06 | 8.366006e+06 | 0.0 | [0.0, 0.0] | ... | 2.3rwdDelay159 | 1.0 | GRADUATED | none | 14.19875 | 11.0 | 11.0 | 17.59875 | 2.0 | 2.0 |
| 1 | 8.366007e+06 | 8.366012e+06 | 0.0 | False | False | 8.366010e+06 | 8.366011e+06 | 8.366011e+06 | 0.0 | [0.0, 0.0] | ... | 2.3rwdDelay159 | 1.0 | GRADUATED | none | 14.19875 | 11.0 | 11.0 | 17.59875 | 2.0 | 2.0 |
| 2 | 8.366012e+06 | 8.366017e+06 | 0.0 | False | False | 8.366015e+06 | 8.366016e+06 | 8.366016e+06 | 0.0 | [0.0, 0.0] | ... | 2.3rwdDelay159 | 1.0 | GRADUATED | none | 14.19875 | 11.0 | 11.0 | 17.59875 | 2.0 | 2.0 |
| 3 | 8.366017e+06 | 8.366021e+06 | 0.0 | False | False | 8.366019e+06 | 8.366020e+06 | 8.366020e+06 | 0.0 | [0.0, 0.0] | ... | 2.3rwdDelay159 | 1.0 | GRADUATED | none | 14.19875 | 11.0 | 11.0 | 17.59875 | 2.0 | 2.0 |
| 4 | 8.366021e+06 | 8.366032e+06 | 0.0 | False | False | 8.366030e+06 | 8.366031e+06 | 8.366031e+06 | 0.0 | [0.0, 0.0] | ... | 2.3rwdDelay159 | 1.0 | GRADUATED | none | 14.19875 | 11.0 | 11.0 | 17.59875 | 2.0 | 2.0 |
5 rows × 47 columns
Let’s see what all is documented here:
trials.columns
Index(['start_time', 'stop_time', 'animal_response', 'rewarded_historyL',
'rewarded_historyR', 'delay_start_time', 'goCue_start_time',
'reward_outcome_time', 'side_bias', 'side_bias_confidence_interval',
'bait_left', 'bait_right', 'base_reward_probability_sum',
'reward_probabilityL', 'reward_probabilityR',
'reward_random_number_left', 'reward_random_number_right',
'left_valve_open_time', 'right_valve_open_time', 'block_beta',
'block_min', 'block_max', 'min_reward_each_block', 'delay_beta',
'delay_min', 'delay_max', 'delay_duration', 'ITI_beta', 'ITI_min',
'ITI_max', 'ITI_duration', 'response_duration',
'reward_consumption_duration', 'auto_waterL', 'auto_waterR',
'auto_train_engaged', 'auto_train_curriculum_name',
'auto_train_curriculum_version', 'auto_train_curriculum_schema_version',
'auto_train_stage', 'auto_train_stage_overridden',
'lickspout_position_x', 'lickspout_position_y1',
'lickspout_position_y2', 'lickspout_position_z', 'reward_size_left',
'reward_size_right'],
dtype='object')
- start_time
Start time of trial (Probably in seconds, relative to some arbitrary clock a long time in the past)
- stop_time
End time of trial (Probably in seconds, relative to some arbitrary clock a long time in the past)
- animal_response
The response of the animal. 0, left choice. 1, right choice. 2, no response.
- rewarded_historyL
The reward history of the left lick spout
- rewarded_historyR
The reward histroy of the right lick spout
- delay_start_time
The delay start time
- goCue_start_time
The go cue start time
- reward_outcome_time
The reward outcome time - when the choice is registered
- bait_left
Whether the left lick spout has a bait or not
- bait_right
Whether the right lick spout has a bait or not
- base_reward_probability_sum
The sum of left and right reward probability
- reward_probabilityL
The reward probability of the left lick spout
- reward_probabilityR
The reward probability of the right lick spout
- reward_random_number_left
The random number used to determine the reward of the left lick spout
- reward_random_number_right
The random number used to determine the reward of the right lick spout
- left_valve_open_time
The left valve open time (probably in seconds?)
- right_valve_open_time
The right valve open time (probably in seconds?)
- block_beta
The beta of exponential distribution to generate the block length
- block_min
The minimum length allowed for each block
- block_max
The maximum length allowed for each block
- min_reward_each_block
The minimum reward allowed for each block
- delay_beta
The beta of exponential distribution to generate the delay duration
- delay_min
The minimum duration(s) allowed for each delay
- delay_max
The maximum duration(s) allowed for each delay
- delay_duration
The expected time duration between delay start and go cue start
- ITI_beta
The beta of exponential distribution to generate the inter-trial interval (ITI) duration(s)
- ITI_min
The minimum duration(s) allowed for each ITI
- ITI_max
The maximum duration(s) allowed for each ITI
- ITI_duration
The expected time duration between trial start and ITI start
- response_duration
The maximum time in which an animal must make a choice in order to get a reward
- reward_consumption_duration
The duration for the animal to consume the reward
- laser_on_trial
Trials with laser stimulation (IGNORE)
- laser_wavelength
The wavelength of the laser (IGNORE)
- laser_location
The target brain areas (IGNORE)
- laser_power
The laser power (IGNORE)
- laser_duration
The laser duration (IGNORE)
- laser_condition
The laser on is conditioned on LaserCondition ? (IGNORE)
- laser_condition_probability
The laser on is conditioned on Laser Condition with probability ? (IGNORE)
- laser_start
Laser start is aligned to an event ? (IGNORE)
- laser_start_offset
Laser start is aligned to an event with an offset (IGNORE)
- laser_end
Laser end is aligned to an event ? (IGNORE)
- laser_end_offset
Laser end is aligned to an event with an offset (IGNORE)
- laser_protocol
The laser waveform (IGNORE)
- laser_frequency
The laser waveform frequency
- laser_rampingdown (IGNORE)
The ramping down time of the laser
- laser_pulse_duration (IGNORE)
The pulse duration for Pulse protocol
- auto_waterL
Autowater given at left lick spout
- auto_waterR
Autowater given at right lick spout
- auto_train_engaged
Whether the auto training is engaged
- auto_train_curriculum_name
The name of the auto training curriculum
- auto_train_curriulum_version
The version of the auto training curriculum
- auto_train_schema_version
The schema version of the auto trainin curriculum
- auto_train_stage
The current stage of auto training
- auto_train_stage_overridden
Whether the auto training stage is overridden
- lickspout_position_x
x position (um) of the lickspout (left-right)
- lickspout_position_y
y position (um) of the lickspout (forward-backward)
- lickspout_position_z
z position (um) of the lickspout position (up-down)
- reward_size_left
left reward size (uL)
- reward_size_right
right reward size (uL)
Behavioral data#
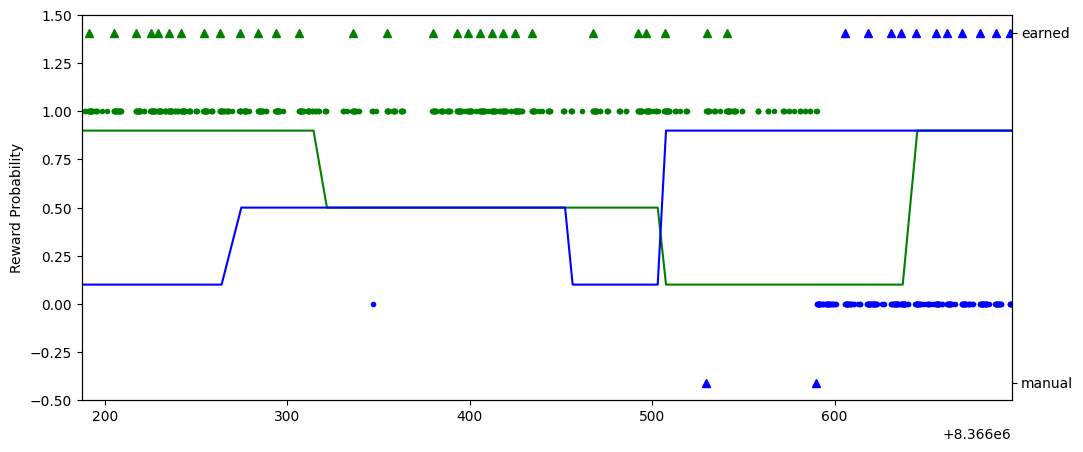
The acquisition element of the nwb file has the lick and reward times for the two lick spouts. Here we plot those events alongside the reward probability for the two sides
fig, ax1 = plt.subplots(figsize=(12,5))
#plot lick times for left and right reward spouts
ax1.plot(nwb.acquisition['right_lick_time'].timestamps[:], nwb.acquisition['right_lick_time'].data[:], 'g.', label="right lick")
ax1.plot(nwb.acquisition['left_lick_time'].timestamps[:], nwb.acquisition['left_lick_time'].data[:]-1, 'b.', label="left lick")
#plot the reward probability of each trial
ax1.plot(trials.start_time.values, trials.reward_probabilityR, 'g', label="right")
ax1.plot(trials.start_time.values, trials.reward_probabilityL, 'b', label="left")
ax1.set_ylabel("Reward Probability")
#plot the reward from right and left spouts on right axis
ax2 = ax1.twinx()
ax2.plot(nwb.acquisition['right_reward_delivery_time'].timestamps[:], nwb.acquisition['right_reward_delivery_time'].data[:], 'g^', label="right reward")
ax2.plot(nwb.acquisition['left_reward_delivery_time'].timestamps[:], nwb.acquisition['left_reward_delivery_time'].data[:], 'b^', label="left reward")
ax1.set_ylim(-0.5, 1.5)
plt.xlim(trials.start_time[20], trials.stop_time[80])
(8366187.101504, 8366697.05248)